The Internet of Things (IoT) has been a buzzword for quite some time now. However, thus far it has not seen wide adoption or market penetration in the home; this, at least, has been my observation. And, in my circle of friends, hardly anyone has adopted any home IoT devices.
Some have flirted with the idea of buying devices like the Nest advanced thermostat, now owed by Google. However, they have not pulled the trigger and actually bought any.
Although I typically tend to be on the early adopter side of the bell curve when it comes to technology adoption-and I believe IoT will be big--I did not have a compelling reason to get into the game with devices for my home, at least until now.
However, when I sat down and connected the dots, I realized that I have a perfect application for an IoT device.
Many parents out there have experienced similar phases in the"going to bed" habits of their kids. My youngest son is in the phase of: Can't go to bed without the light on.
He just traded with his older brother, who no longer has this problem. However, the light my little one "demands" cannot merely be a nightlight. It has to be a fairly bright light to satisfy him.
Obviously, I do not want to have the light on all night for two reasons:
- It is not good for his sleep
- It is a waste of energy (even though I use CFLs)
Hence, the typical nighttime drill is this:
- Potty time (use the toilet for you non-US folks out there)
- Teeth brushing
- Storybook reading
- Waiting until he is in a deep sleep and returning to shut his light off
This routine works pretty well, but sometimes turning the light off wakes him up. There ought to be a better way, and there is.
The other night I was too tired to walk over to turn off his light. But I still did it.
However, I thought that this is too stupid a method to be using in 2014 - I needed to automate this process. So I searched around and found a smartphone-controllable LED light bulb for his room with the associated controller hub! Specifically, I got the TCP Connected smart lighting system.
The experience was amazing. The hub setup was trivial and the app is very user friendly. You can witness my first test in the video below.
Besides the buzz and the general interest in the space, IoT in general and home automation in particular, it's not just marketing hype--there are serious dollars behind it. One recent example is the $90M cash infusion into a company called Savant. Further on, Apple announced an API for this space called HomeKit at their developer conference in June.
It seems that home automation with IoT devices is about to take off.
However, one of the challenges to IoT home automation adoption is that old habits are hard to break. Even I, typically an early adopter of technology, sometimes get stuck in old and inefficient ways of performing a task. To this day I still tend to use vi when editing code on Linux-It is my default mode of operation.
And, while I am fully aware of the advantages in editing e or SystemVerilog code using an IDE such as Eclipse, particularly when it is extended for the use of HVLs with DVT, it still takes a special effort to move away from such true and trusted approaches in order to gain additional automation and productivity.
Many design and verification engineers follow similar habits. For example, when debugging code they spike it with lots of print statements and then peruse the resulting log file.
There is nothing wrong with this approach in and of itself--it is a classic and trusted method that gives the developer the information he or she wants, while being productive.
However, since code is getting continually more complex, like HDLs mixed with HVLs and so on., one quickly gets caught up in what can appear to be an infinite iterative loop. For example, because of a log message A, the developer now needs additional information, such as the value of a variable B, and so on. Consequently, the code has to be edited and re-edited, and the simulation has to run again and again.
With a small verification environment, such iterations can be fairly quick. However, at a complex sub-system level, such iterations might take several minutes, or even hours, which can add up very quickly to a lot of frustrating wait time.
Besides frustration and wasted time, debugging iterations like this can also reduce productivity in other ways. Debugging is a very complex and intellectually demanding task. Any interruption or wait time will reduce the debug progress. The person debugging has certain thoughts and assumption she uses in determining the cause of a failure. If it takes a long time to get answers to these assumptions, then the debug productivity is adversely affected. In other words, the human idea caching is reduced.
It is exactly for this reason that Cadence introduced Incisive Debug Analyzer.
With Incisive Debug Analyzer, large portions of the productivity problems inherent in iterated debugging are addressed. Many of the debug iteration loops are cut out of the process altogether. One still needs to annotate the code with debug messages. But those messages become smart log messages.
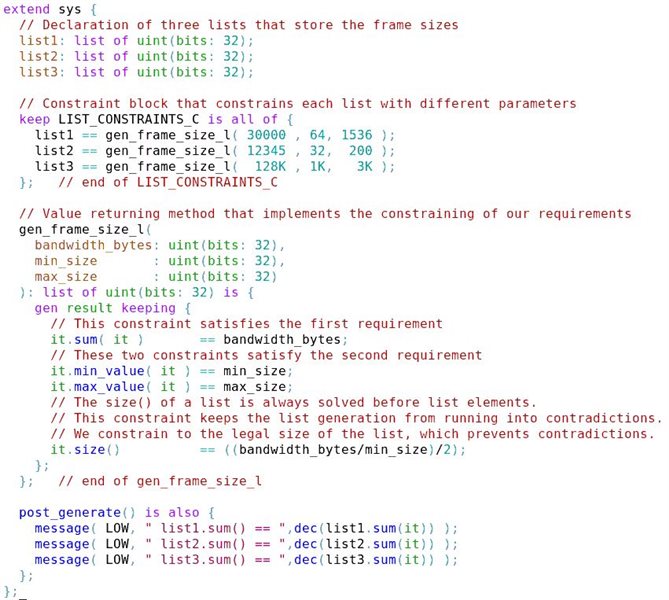
A smart log message is an advanced log message that can come from multiple sources, be it HVL such as e [IEEE 1647] or SystemVerilog [IEEE 1800], HDL, C, C++ or even assertions.
A powerful feature of Incisive Debug Analyzer smart logging is that it allows you to change the verbosity level of log messages without having to re-run the simulation. Incisive Debug Analyzer contains numerous other features that let you interact with log messages to hone in on the root cause of a bug more quickly. Smart logs are also synced up with the waveform database, providing a consistent view of the current simulation time.

In addition, Incisive Debug Analyzer enables effective interactive debugging. For example, assume you are stepping through a simulation and you halt using a breakpoint. If you now advance the simulation accidentally, or if you halted because of a wrong assumption, you might have to start the simulation all over again.
With Incisive Debug Analyzer, however, you can move both forward and backward through simulation time, reducing many simulation runs. You can do this because the HVL and HDL code is not being simulated. Instead, recorded values in the Incisive Debug Analyzer database are being stepped though. Consequently, the execution through time is orders of magnitude faster than in a live interactive simulation.
These are just some of the ways Incisive Debug Analyzer can help your debug process. For a full description, check out this link.
Bottom Line: Incisive Debug Analyzer can increase your debug productivity by automating a classic and manual debug process.
Long live efficiency!
Axel Scherer
Incisive Product Expert TeamTwitter, @axelscherer